The Verification Stack
.png)
Written by
Xingyao Wang, Calvin Smith
Published on
Written by Xingyao Wang, Calvin Smith
Published on May 6, 2026
Agents made generating code cheap. The real bottleneck is now verification: checking that a change is correct, follows repo conventions, and is something your team can trust, review, and merge.
In this post we introduce our solution to this problem: the verification stack, a set of automated verifiers that catch different kinds of mistakes at different stages, so coding agents fail fast and humans only spend time on changes worth merging. In this post, we introduce the various levels of the stack, and explain how you can run it yourself in your own coding projects.
The verification stack
The verification stack is designed around a simple insight: agents make different kinds of mistakes, which are best caught at different stages in the process. Issues regarding the agent's work itself (the agent went off-track, misunderstood the task, or got stuck in a loop) can be caught before code is pushed by simply looking at the agent's trajectory of actions. Repo-level issues (style violations, missed edge cases, convention drift) should be caught during code review, as part of the normal PR workflow.
**Layer 1 — Agent-Level Verifier (Critic Model): **A small, fast model that scores the agent’s work before code is pushed, gating obviously broken work. Trained on real production traces, it achieves a high accuracy on predicting outcomes on our production data.
**Layer 2 — Repo-Level Verifier (code review & QA bot): **An automated code reviewer that triggers on every pull request. It consists of a code review skill that provides inline comments, catches bugs, and enforces best practices, plus a QA agent that functionally verifies changed behavior.
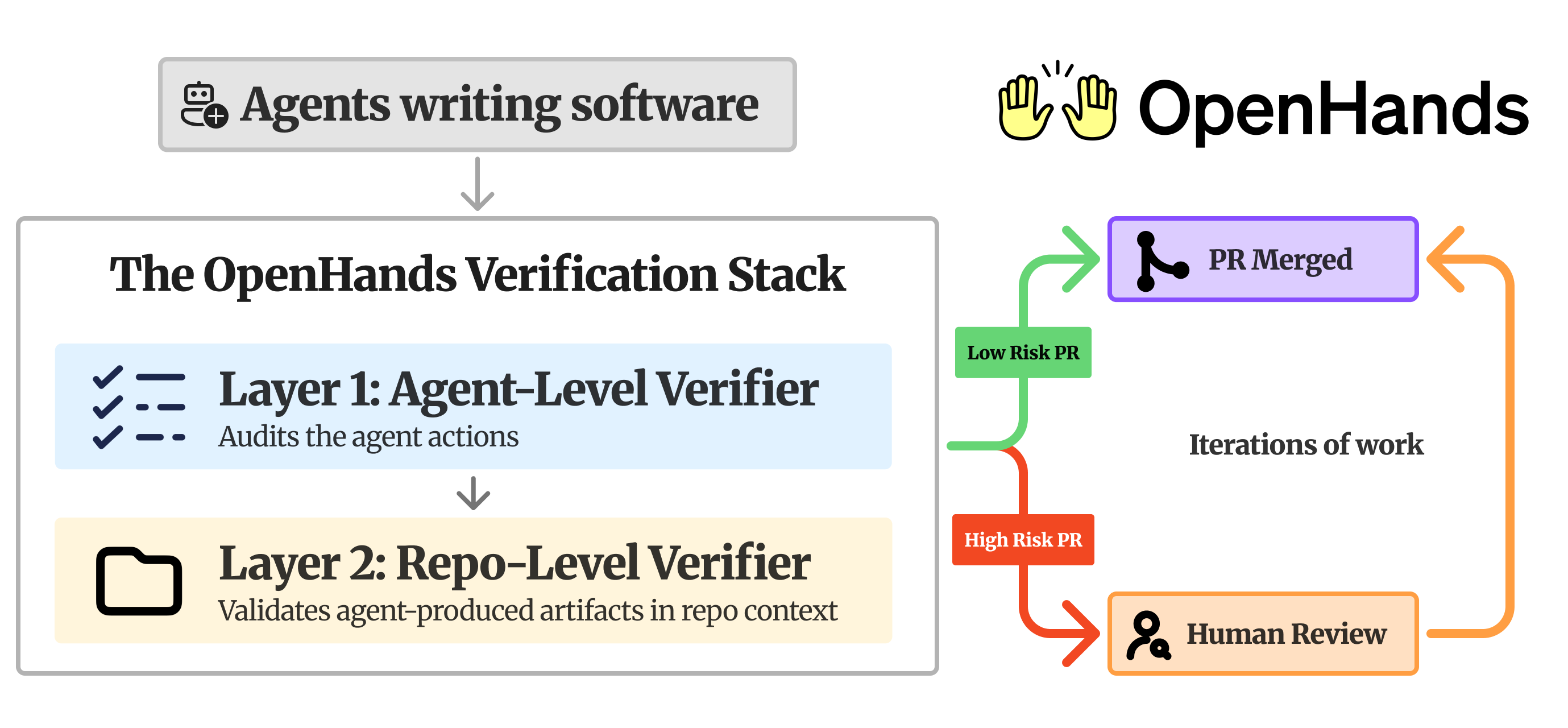
The agent-level verifier: OpenHands critic model
The critic model is a verifier that runs while the agent is still working, before any code is pushed. As the agent takes actions, the model scores how likely the run is to succeed. OpenHands acts on that score: a low score can stop the run early, or trigger the agent to retry, so a broken attempt never reaches a human reviewer. For more detail on how we trained this model and measured its accuracy, see our previous blog on Learning to Verify AI-Generated Code.
The repo-level verifier: OpenHands code review & QA agent
The repo-level verifier consists of two components — a code review agent and a QA agent — both built as plugins in the OpenHands Extensions repository. When a PR is opened or marked ready for review, they run automatically against the diff.
The code review skill
The reviewer is driven by a detailed code review skill that encodes the analysis framework. It applies a structured checklist of 10 review scenarios, prioritized by impact. The four highest-priority categories:
-
Data structure analysis (highest priority) — flags poor data structure choices that create unnecessary complexity
-
Security and correctness — real risks (unsanitized input, hardcoded secrets, race conditions), not theoretical ones
-
Testing gaps — rejects mock-only tests; requires tests that exercise real code paths and assert on outputs
-
Dependency and supply chain risk — checks new or downgraded dependencies for release provenance and known vulnerabilities
Every review ends with a risk assessment (🟢 Low / 🟡 Medium / 🔴 High) and a verdict. High-risk PRs are flagged for human architect review rather than auto-merged.
Crucially, the review skill is customizable per repository. Teams can add a .agents/skills/custom-codereview-guide.md file to teach the reviewer about project-specific conventions. The reviewer reads this from the PR branch, so guideline changes take effect immediately on re-review — creating a continuous improvement loop.
The QA agent
Unlike the code review agent which reads diffs, the QA agent actually runs the software. It follows a four-phase methodology:
-
Understand — reads the PR diff, title, and description; classifies changes and identifies entry points (CLI commands, API endpoints, UI pages)
-
Setup — bootstraps the repo: installs dependencies, builds the project
-
Exercise — the core phase: spins up servers, opens browsers, runs CLI commands, makes HTTP requests — testing the changed behavior as a real user would
-
Report — posts a structured QA report as a PR review, with evidence (commands, outputs, screenshots) and a verdict
The QA agent knows when to give up: if an approach fails after several materially different attempts, it switches strategy. If multiple fundamentally different approaches fail, it reports honestly what couldn’t be verified. Like the code reviewer, it can be customized via AGENTS.md or custom skills in .agents/skills/.
How effective is it? Evidence from production
We’ve been running the code review bot on the OpenHands/software-agent-sdk repository for six months. In that time, the code review bot published over 1,000 reviews across 900+ PRs and 38 releases, and has become a critical part of our infrastructure.
Let’s look at the numbers to see how that impacted our software development process.
Growing adoption leads to higher velocity
Full adoption of the code review bot took several months. But now 90% of all PRs use the automated review process in some capacity, and 23% go through multiple review rounds.
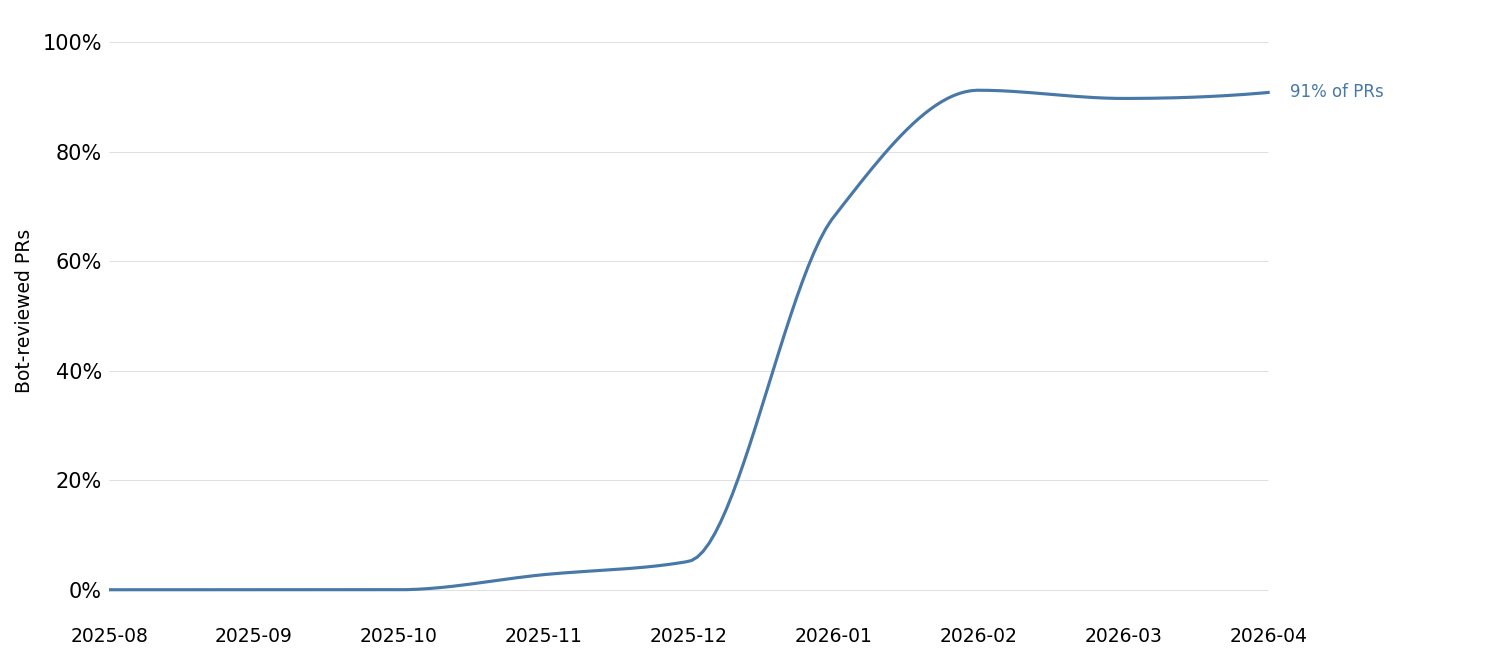
Those PRs that abstain are usually small (median diff size of 34 lines), and represent maintenance tasks like updating dependencies or tweaking constants.
Since the introduction of the code review bot, our development velocity has increased. The bot is almost always the first review, and the instant feedback helps the author address any immediate issues by the time a human takes a look.
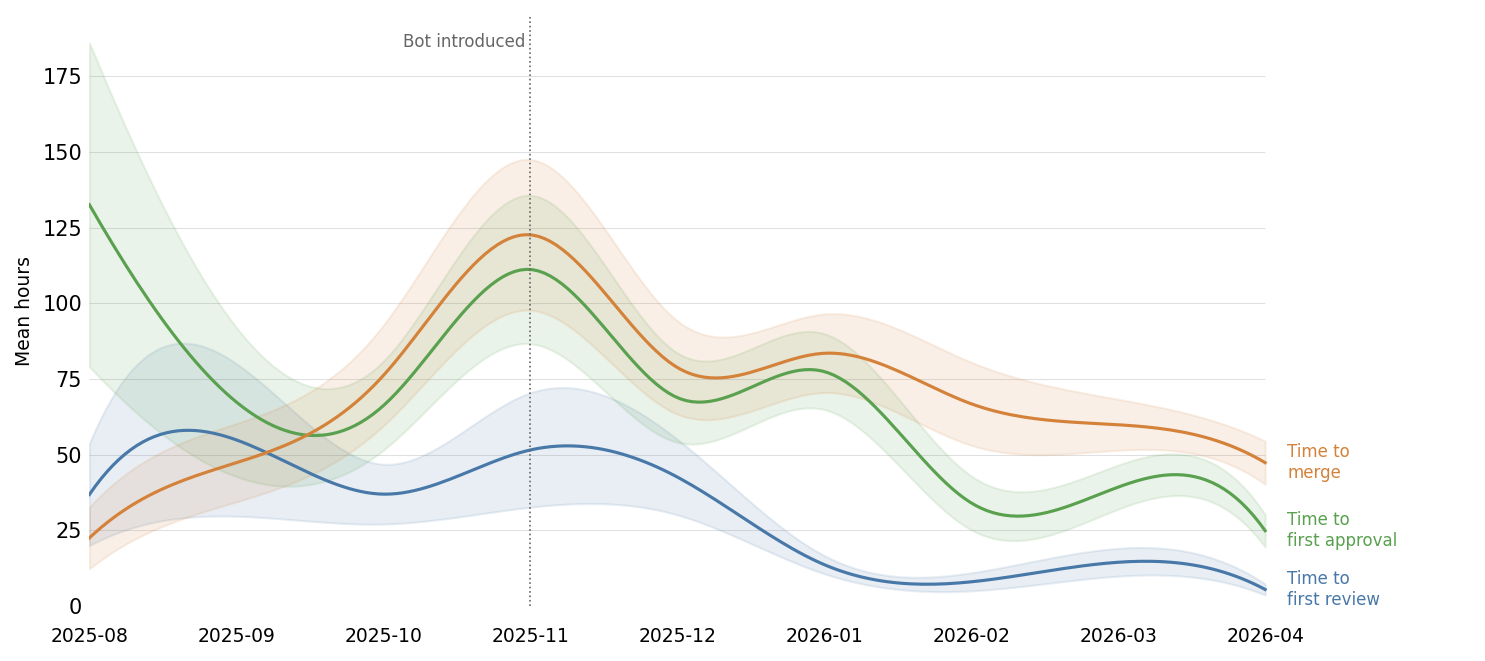
This reduces friction for the PR author and the reviewer, and the result is every part of the PR pipeline moves faster. Since introducing the code review bot, our mean time to merge has been reduced by 58%.
Approaching human-quality reviews
You cannot replace quality reviews with a high quantity of reviews. To see if code review bot was a positive contribution to the review process, we built an evaluation pipeline that:
-
Uses an LLM-as-judge to extract a list of suggestions from each PR, noting whether it came from code review bot or a human, and whether it was reflected in the merged diff, and
-
Computes precision (portion of code review bot suggestions actually incorporated) and recall (portion of incorporated suggestions proposed by code review bot). We also treat PRs with no suggestions as having perfect precision — sometimes an “LGTM” is all that is needed.
To put these metrics into perspective, we’ll compute the precision of human reviewers during the same time span.
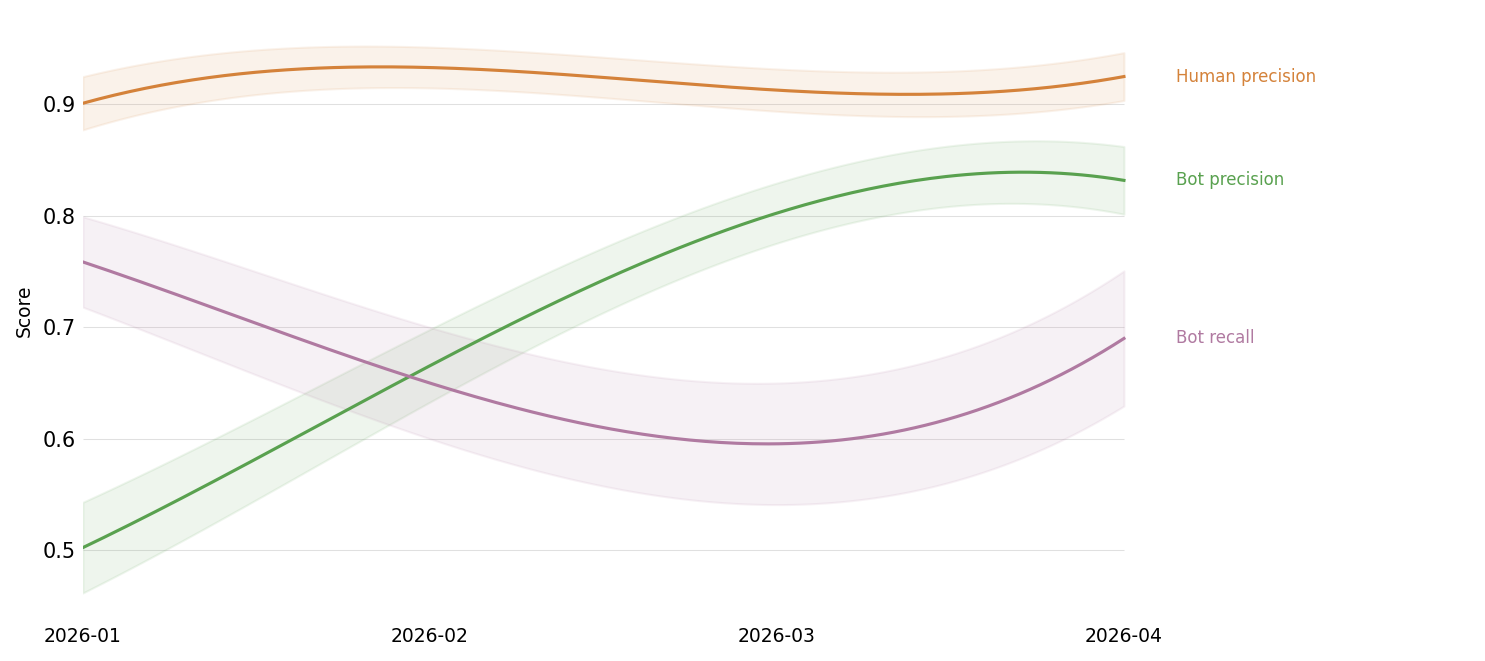
We’ve continued to iterate on the code review bot’s behavior and infrastructure, as seen in the consistent improvement over time. The bot’s precision is approaching human-level: impressive, considering that 85% of the time humans review a PR after the bot has already left its comments.
We’ve only plotted the code review bot’s recall, but that’s because the way we’ve defined it is zero-sum: if the bot has high recall, the human reviewers must have low recall, and vice versa. So recall above 0.5 indicates that code review bot is contributing a majority of suggestions that get incorporated into the final PR.
Keeping code quality high
A skeptic might be reasonably concerned that the code review bot is increasing our development velocity at the expense of code quality.
Fortunately, we find this not to be the case. Using a combination of static analysis tools (radon, bandit, and ruff), we can examine how our repository’s code quality has changed since the introduction of code review bot.
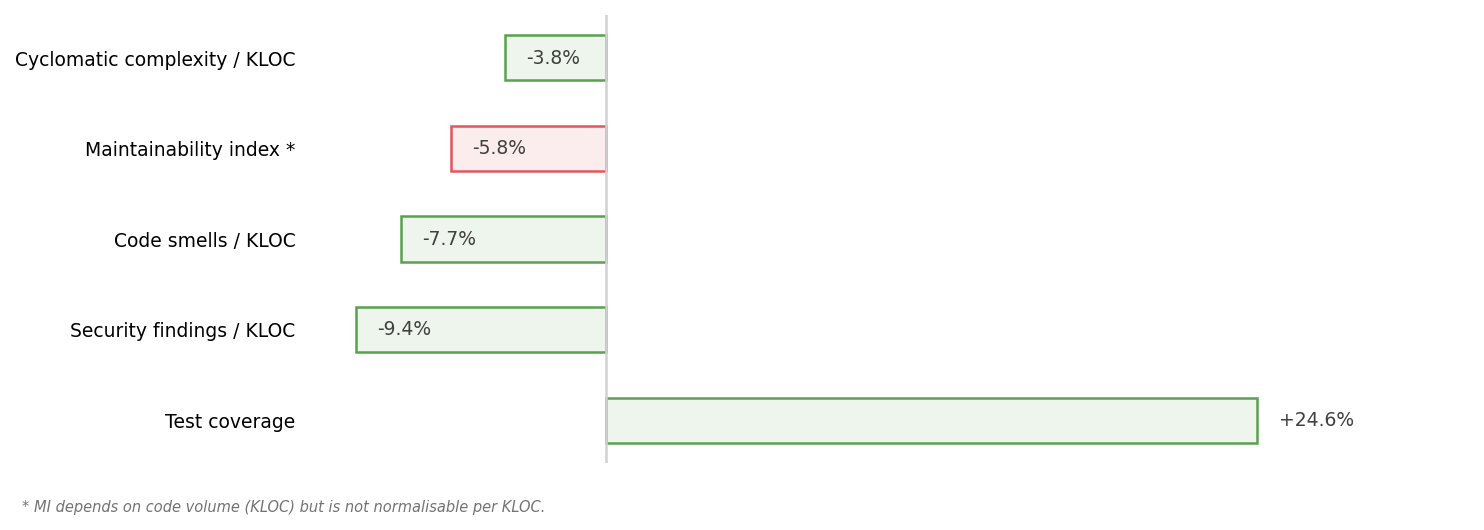
All the things you don’t want in code — cyclomatic complexity, code smells, potential security vulnerabilities — are way less prevalent. And the code review bot makes sure new functionality doesn’t get added without tests, so our coverage has increased by nearly 25%.
The only metric we’ve found to decrease is the Maintainability Index. But lines of code count against maintainability, regardless of their quality, and over the same interval the repository grew 144% from 61 KLOC to 148 KLOC.
Closing the loop: the iterate skill
Setting up the verification stack is only half the story. The other half is acting on it: reading CI results, parsing review comments, fixing code, pushing again, repeating until everything’s green. For humans that’s the tedious babysitting phase of a PR. For an agent it’s just a loop, and the iterate skill runs it.
Invoke /iterate on a PR or branch and the agent opens a draft PR (so auto-merge and deploy don’t fire early), runs whatever verification layers the repo has, fixes what they flag, and pushes again. It repeats until everything passes, then marks the PR ready. Pair it with OpenHands Automations to run it on every PR, so the mechanical checks are done before a human looks. Find the skill in OpenHands/extensions.
Bring the full verification stack into your workflow
The verification stack is ready to use today. It has two complementary layers: the agent-level critic catches broken agent runs before code is pushed, while the repo-level verifier reviews and tests pull requests inside your normal development workflow.
**Layer 1 — Agent-level verification. **The critic model is available in OpenHands Cloud and Agent Canvas today. In Settings, open the Verification tab, turn on Enable Critic, and save. To take it further, enable Iterative Refinement so OpenHands can automatically retry a task when the critic score falls below your threshold.
**Layer 2 — Repo-level verification. **The repo-level verifier can be wired into your repositories in two ways:
-
GitHub Actions, per repository. Add a workflow under
.github/workflows/and the code review bot runs on every PR as part of CI (instructions: https://docs.openhands.dev/openhands/usage/use-cases/code-review). This gives you full control over when and how it runs, while keeping setup explicit for each repo. See Automated Code Review for the full walkthrough. -
OpenHands Cloud Automations, org-wide. Define the review workflow once and trigger it across every repository your bot account can access (instructions: https://docs.openhands.dev/openhands/usage/use-cases/code-review#option-b-openhands-automation-org-wide). This path runs inside the full OpenHands Cloud sandbox, with your configured skills, MCP integrations, and repository knowledge available to the reviewer. See Setting up event-driven automations for setup details.
Together, these layers turn verification from a one-off review step into a continuous loop: catch bad trajectories before they become PRs, review changes against repo-specific expectations, run QA against the actual behavior, and iterate until the change is ready for a human reviewer.
If you’re deploying OpenHands in a team setting and want to bring this verification stack into your workflow, we’d love to hear from you. Contact us and we can help you set up the right combination of critic, code review, QA, and automations for your repositories.
Resources
-
Learning to Verify AI-Generated Code — Layer 1 (agent-level verifier) deep dive
-
OpenHands Enterprise: The Agent Control Plane — Automations announcement
-
OpenHands Extensions repo — Code review skill and QA agent
-
Critic model paper — Technical details on the agent-level verifier

Get useful insights in our blog
Insights and updates from the OpenHands team
Sign up for our newsletter for updates, events, and community insights.
OpenHands is the foundation for secure, transparent, model-agnostic coding agents - empowering every software team to build faster with full control.



