AI Code Analysis in 2026: What It Is, How It Works, and Top Tools
Written by
OpenHands Team
Published on
Your linter doesn't know that the discount is applied before the cart total is validated. Neither does your SAST scanner. The bug ships because every line is syntactically correct — the mistake lives in the relationship between two files that no rule was written to check.
That's the class of problem AI code analysis was built for, and it's why engineering teams are adding reasoning-based tools on top of the rule engines they already run.
What is AI code analysis?
AI code analysis uses LLMs and agentic systems to evaluate, modify, and reason about source code based on its behavior rather than its surface syntax. The category has grown beyond autocomplete and SAST (static application security testing) wrappers into agent-driven tools that act on findings instead of filing them as static reports.
AI code analysis is broader than AI code review, which is the pull-request-facing slice. The category also covers security scanning, code quality scoring, performance profiling, and refactoring work.
Three things separate the current generation of analyzers from the rule-based tools that came before:
-
Reasoning over pattern matching: Mitch Ashley of The Futurum Group framed it as a shift from catching known-bad signatures to catching code that behaves incorrectly relative to intent. Reasoning-based analyzers target a different class of bug than pattern matchers do.
-
Comprehension, detection, and remediation in one pass: Traditional SAST handled defect detection and handed everything else back to humans. Modern analyzers read the code, find the bug, and propose a fix inside a single context.
-
Agentic initiative: New analyzers act on their findings instead of writing reports for someone else to read. They open files, run tests, query type servers, and revise hypotheses across multiple turns.
Teams moving off rule-based scanners tend to notice first in the review queue: fewer round-trips, fewer false positives punted to the next sprint.
How AI code analysis works under the hood
If you're evaluating these tools, you don't need to understand every layer of the architecture — but knowing the basic loop helps you ask better questions during a vendor call. Here's what's happening behind the scenes.
Retrieval and chunking. The system walks call graphs and import chains to gather the snippets most relevant to a query, then feeds them to an LLM. Chunking strategies that respect function and class boundaries tend to outperform naive line-count splitting, because the model reasons better when it sees complete semantic units rather than arbitrary slices.
Structural grounding. Retrieval alone produces plausible answers that sometimes reference functions that don't exist. Abstract syntax tree (AST) traversal and language server protocol (LSP) lookups close that gap by giving the model verified structural facts — symbol definitions, types, call sites — with compiler-grade precision. Those facts get woven into the prompt so the model's claims are constrained by what the toolchain can confirm.
Sandboxed execution. The analyzer validates a generated patch by actually running the code. Sandboxed environments let the analyzer execute candidate fixes against the test suite, iterate when assertions fail, and summarize long sessions when they risk exceeding the context window. The CodeAct paper formalized this pattern — representing agent actions as executable Python — and showed it improves agent task completion rates.
The overall loop is retrieval → reasoning → action → verification, repeated until the fix holds or the agent reports what it couldn't resolve.
The four tiers of AI code analysis
AI code analysis tools fall into four tiers based on how much reasoning they do beyond pattern matching. Most teams run tools from two or three tiers at once.
Tier 1: Rule-based static analyzers
SonarQube, ESLint, and Semgrep are pattern-matching engines backed by predefined rule libraries. They're fast and predictable, but they cannot detect anything outside their rules. (Semgrep's Multimodal mode layers LLM reasoning on the rule engine, which starts to blur the line with Tier 2.)
Tier 2: AI-augmented SAST
Snyk Code and Checkmarx represent traditional SAST with machine learning bolted onto triage and remediation. The core detection still runs on rules and a curated taxonomy of common weakness enumerations. The ML layer adds noise reduction and auto-generated fixes for issues the rules already flagged.
Tier 3: AI-native pull request reviewers
CodeRabbit and Greptile are LLM-first reviewers that read PR diffs — sometimes the full repository — using semantic reasoning instead of a rule library. They generate inline review comments, propose fixes, and answer follow-up questions in the PR thread. Reasoning about intent lets them catch logic issues a linter would miss.
Tier 4: Autonomous code analysis agents
Autonomous agents detect issues, diagnose root causes, write patches, run tests, and open PRs without a human between steps. They work in the outer loop — running in the background between developer sessions — while IDE tools like Cursor and CLI agents like Claude Code or Codex handle the inner loop with a developer at the keyboard.
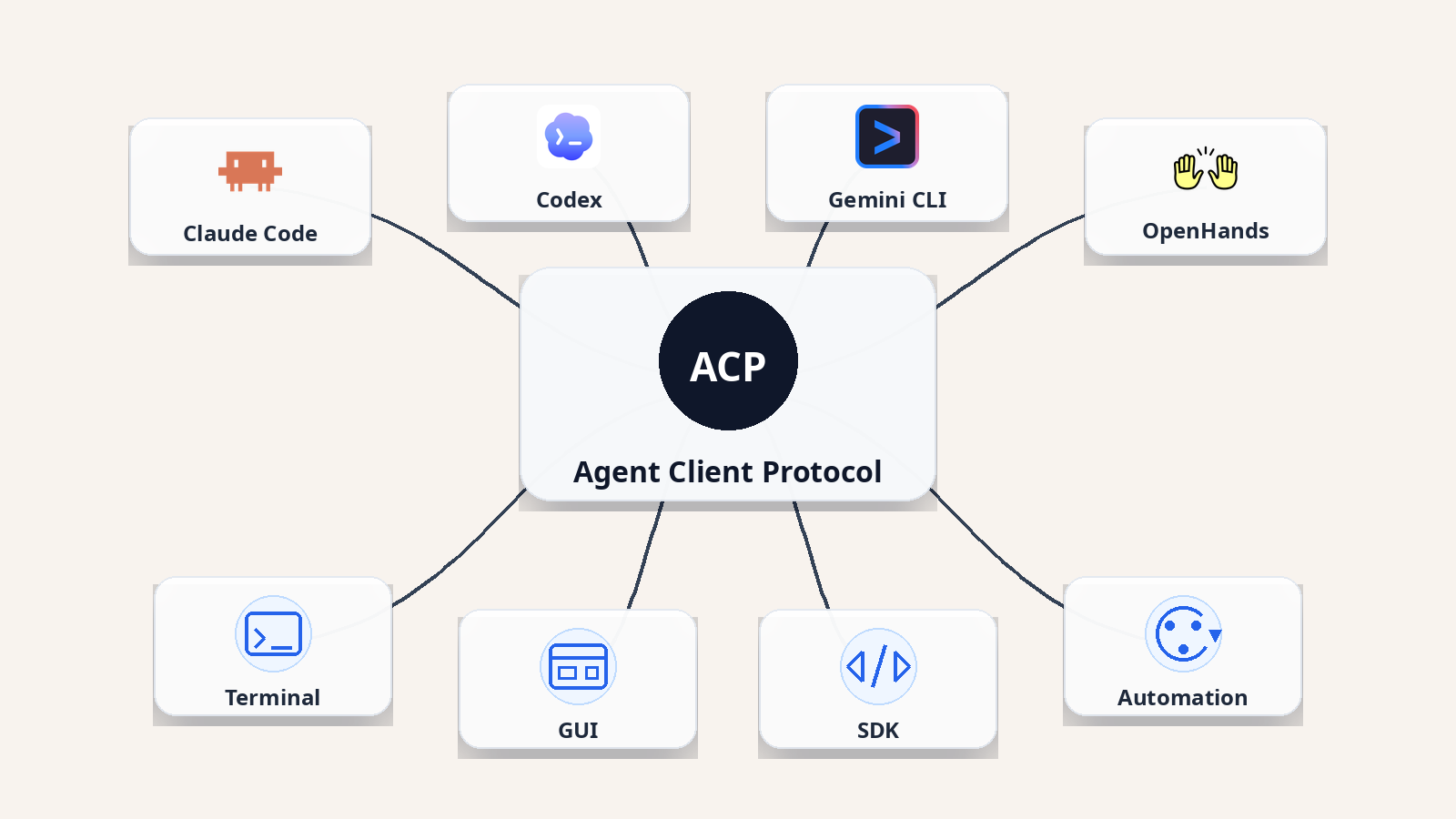
OpenHands is the open-source platform for building and running these agents. It's model-agnostic, connecting to Claude, Codex, Gemini, and others through the Agent Client Protocol, and it runs each task in a sandboxed environment so agents can execute code, run tests, and iterate on failures without touching your production systems. You can run it locally, in OpenHands Cloud, or self-hosted in your own VPC.
What AI code analysis catches that rule engines miss
Rule-based scanners work well on known patterns. They struggle with anything that requires reasoning about intent, context, or code that doesn't exist yet. Here are four gaps that pattern matchers can't reach:
Business-logic flaws and intent mismatches. A discount applied before cart-total validation, or a token check that ignores the expiration field, passes any linter without warnings. No rule engine can flag business logic it was never taught. An LLM reading the surrounding code is the first reviewer with a realistic chance of catching the mismatch.
Cross-file and architectural drift. A refactored JWT helper with a permissive default, silently inherited by downstream microservices, is locally correct in every file. Cross-file AI analysis catches the semantic contract break by reasoning across the call graph.
Vulnerabilities in AI-generated code. LLMs hallucinate package imports — a 576,000-sample evaluation across 16 LLMs (USENIX Security 2025) found hallucination rates of 5.2% for commercial models and 21.7% for open-source models. Attackers register the fabricated package names with malicious payloads, and software composition analysis (SCA) tools can't flag a package that doesn't yet exist in the real registry.
Performance and concurrency bugs that need runtime context. Race conditions between concurrent Lambda invocations, or scope-elevation bugs where a refactor turns a utility into a singleton, look correct when each file is reviewed in isolation. An analyzer that reasons about runtime topology catches what single-file review cannot.
These four bug classes share a trait: they live in the relationships between pieces of code, which is why line-by-line scanners don't reach them.
Where to deploy AI code analysis in the workflow
AI code analysis fits three surfaces, and teams typically adopt them in order:
In the IDE — catching issues at the point of creation, before anything lands in version control. This is the lowest-friction starting point: one developer, one editor, immediate feedback.
At pull request time — a reasoning pass that combines AI judgment with deterministic checks as a quality gate. This is where most teams standardize first, because it fits the existing review workflow.
As background agents — handling vulnerability remediation, dependency bumps, and large-scale migrations in parallel, without blocking the team on day-to-day work. This is where the autonomy in Tier 4 pays off: work that would sit in the backlog for weeks runs overnight.
The progression is IDE first, then PR checks once shared standards exist, and finally background agents once trust in the model and the sandbox is in place.
Notable AI code analysis tools to know in 2026
The market splits across static analyzers with AI fix layers, security-first scanners, AI PR reviewers, and autonomous agent platforms. Here are five tools that come up most often when teams are evaluating options.
OpenHands
OpenHands is an open-source platform for autonomous code analysis agents — the kind of tool described in Tier 4 above. Agents scan repos, write fixes, run tests in a sandboxed environment, and open PRs. It supports multiple LLM providers through the Agent Client Protocol and can run locally, in OpenHands Cloud, or self-hosted in your VPC.
OpenHands appears on the SWE-Bench Verified leaderboard across multiple configurations, and it provides a full autonomous loop from finding through applied fix, test run, and opened PR. For org-scale work, the Enterprise Agent Control Plane adds orchestration, audit logs, RBAC, and self-hosted deployment.
Best for platform engineering teams that need auditable, self-hosted agents for security remediation and backlog burndown.
SonarQube
SonarQube is a rule-based static analysis incumbent that has started layering AI on its core engine. Its AI-powered remediation features generate LLM-based fix suggestions inside SonarQube workflows, though the loop stops at the suggestion — it doesn't carry the fix through to a merged PR.
SonarQube covers 40+ languages and frameworks with rule packs maintained by SonarSource, and findings flow into the same dashboards security and engineering teams already use.
Best for teams already running SonarQube in CI who want AI fix suggestions without replacing their SAST pipeline.
Snyk Code
Snyk Code pairs ML with curated security knowledge to surface exploitable issues across application and infrastructure layers. Snyk Agent Fix provides autonomous remediation for detected vulnerabilities as a hosted service. Coverage spans SAST, SCA, infrastructure as code, and containers, with editor and PR integrations that tie findings into existing developer workflows.
Best for DevSecOps teams that want security-first SAST inside developer workflows.
CodeRabbit
CodeRabbit reviews pull requests by combining LLM reasoning with deterministic scanning. It integrates 40+ linters and scanners across the review pipeline, supports GitHub, GitLab, Bitbucket, and Azure DevOps, and uses adaptive learning to tune reviews based on past feedback. Output lands as a comment thread with inline suggestions.
Best for multi-platform teams that want a single AI reviewer across providers.
Semgrep
Semgrep is an open-source rule engine with AI-augmented triage through Semgrep Multimodal, which mixes deterministic SAST with LLM reasoning. It supports customizable YAML rules for encoding org-specific patterns and offers multi-LLM provider flexibility for swapping the reasoning model behind triage. The deterministic engine still anchors all findings.
Best for AppSec-mature teams with security engineers who maintain custom rules.
How to roll out AI code analysis without breaking the team
Most rollout trouble traces back to four recurring issues:
Missing baselines. Capture your defect escape rate, mean time to resolution, and review cycle time before the pilot starts. Aim for a false positive rate under 10% within the first month, and walk back the scope if you miss.
Alert fatigue. When SAST tools fire on every commit, developers stop reading the output. Wiring an AI interpreter into the triage step can cut noise substantially — the model filters findings that are technically correct but practically irrelevant, and escalates the ones that matter.
Over-trust on autonomous output. AI analysis still misses domain-specific logic and edge cases that human reviewers catch. Keep a mandatory human gate on security-critical paths, payment flows, and anything touching authentication.
Governance gaps. Shadow AI spreads when adoption is developer-by-developer. Each AI agent should be treated like a user persona: role-based access controls, resource quotas, and audit logging from day one.
An instrumented pilot that expands only after the metrics hold for two consecutive sprints tends to outperform a wider enterprise rollout.
How OpenHands approaches AI code analysis
Running AI code analysis in production raises operational questions a single-developer setup doesn't have to answer: where do agents execute, what can they access, and who audits their actions?
OpenHands addresses these through an autonomous loop — an agent reads the repository, identifies defects, generates a fix, runs the test suite in a sandbox, and opens a PR. Before that PR reaches a human reviewer, it goes through a two-tier review process: the person who invoked the agent reviews the draft, then a second human reviewer signs off. The two-pass structure catches the mistakes agents still make on domain-specific logic.
For org-scale work, the Enterprise Agent Control Plane adds orchestration across repositories, audit logs, RBAC, and cost controls. Agents can run across a fleet of repos in parallel — useful for dependency bumps, vulnerability remediation, and large migrations.
The primary interface is Agent Canvas, a local-first visual workspace that connects to Claude Code, OpenAI Codex, and Gemini CLI through the Agent Client Protocol. You keep your existing tools, models, and subscriptions.
Bringing AI code analysis into your workflow
Pattern-matching tools still earn their place. Rules give you determinism and zero hallucination risk on known vulnerability classes. AI gives you reasoning about intent, cross-file context, and the kind of business-logic mistakes rules were never taught to catch. Human review covers the paths touching money, identity, and data — the ones where getting it wrong has consequences beyond a failed test.
The teams that get this right run all three layers and treat them as complementary, not competing. The rule engine is the floor, the AI is the ceiling, and humans own the judgment calls.
If you're starting from zero, start small: install OpenHands locally with Agent Canvas and the coding agent you already pay for. Ship one repeatable automation — a dependency bump, a lint fix across a module — and see how the output holds up under review. The pricing page covers the three deployment options (open-source local install, free SaaS tier, self-hosted enterprise) once you're ready to scale.
Frequently asked questions about AI code analysis
Do I still need human code review if I'm running AI analysis?
Yes. AI handles pattern checks, security scans, and routine refactoring at a scale humans can't match, and it runs the same passes consistently across large codebases. Humans bring organizational context and catch novel threats outside the training distribution. The question isn't which one to pick — it's how to divide the work so reviewers spend their time on judgment calls instead of style nits.
Can AI code analysis replace SonarQube?
Probably not, and you probably shouldn't try. Deterministic rule engines catch known patterns with zero hallucination risk, which matters for compliance reporting and license-style gates. AI catches business-logic flaws and cross-file drift that rules can't encode. Most teams end up running both: the static engine covers the known catalogue, and an autonomous agent handles the open-ended findings that rules don't reach.
How does AI code analysis handle large monorepos?
A monorepo with millions of lines doesn't fit any context window. Analyzers handle this through retrieval-augmented generation (pulling in only the relevant code), hierarchical summarization (condensing older context as the session grows), and parallel agent orchestration (running agents on different modules simultaneously). The OpenHands SDK supports coordinating those parallel runs and assembling results for review.
Is it safe to let AI analyze proprietary source code?
It depends on where the inference happens. Cloud-only tools transmit source code to external infrastructure, which can be impermissible under ITAR, HIPAA, or financial-services rules. Self-hosted deployment with a local model endpoint keeps code and inference data inside your perimeter. OpenHands Enterprise supports deployment on AWS, GCP, or Azure in your own VPC — the same platform, without source leaving your environment.
.png)

Get useful insights in our blog
Insights and updates from the OpenHands team
Sign up for our newsletter for updates, events, and community insights.
OpenHands is the foundation for secure, transparent, model-agnostic coding agents - empowering every software team to build faster with full control.



