Best Way to Get AI to Completely Refactor Frontend Code (2026)
Written by
OpenHands Team
Published on
Frontend refactors that touch more than a handful of files are some of the slowest work on any team's roadmap. A typical mid-size React app has four near-identical button components, state management spread across two libraries, and an App Router migration the team has been putting off for two quarters. The button consolidation might take a few days, but the state library migration and the App Router move each run into weeks of senior engineering time — and they keep getting bumped by feature work.
Agents can do the mechanical parts of this work. We've watched many teams run these refactors through OpenHands, and the pattern is clear: the ones that succeed don't use better models — they use better setup. The contract you give the agent, the CI gates around it, and the batch size you pick matters as much as the LLM running under the hood. Here's the workflow that actually gets refactors across the finish line.
Why chat-based AI breaks down on multi-file frontend refactors
Chat assistants are tuned for a single turn against a single file. A frontend refactor crosses dozens of files, shared types, and a component tree where one rename touches multiple call sites. The failures show up in three places:
Context windows fill up fast. Five or six component files, a types directory, and a couple of test specs crowd out the original instructions. Martin Fowler's writing on context anchoring covers how quickly that happens in a working session — the agent forgets what you told it three files ago.
Single-file edits drift across the component tree. The assistant rewrites Button.tsx with a new prop signature, then rewrites IconButton.tsx using a different signature without realizing the two components share a contract. Research on lost-in-the-middle attention shows why: models pay less attention to the middle of their input, which is exactly where earlier edits sit by the time the agent reaches file six.
Hallucinated imports compound. Simon Willison's writeup on hallucinations in code covers the basic failure — the model imports a library that was never installed or calls a method that doesn't exist. In a single-file edit that's one easy-to-catch error. Across a refactor, those fabrications stack up, and you end up debugging a build failure three components downstream whose root cause is a hallucination from earlier in the session.
Each failure gets worse as the refactor grows. The fix isn't a better model — it's a more careful setup before the agent edits anything.
6 steps to get AI to completely refactor frontend code
The six steps below cover the preparation before the first prompt, the workflow that runs after, and the decision about which refactors fit this approach.
Step 1: Define the scope and success criteria before any edits
Before the agent reads a single file, write down what you want changed and how you'll know it worked. Without a written contract, there's no way to evaluate the diff the agent produces.
Refactors fall into three tiers of risk. Cosmetic work — renaming variables, tightening prop types — is mostly safe with light review. Structural work — splitting a 2,000-line component, reshaping a Redux store — needs human review on every meaningful diff. Framework migrations — class components to hooks, Webpack to Vite — are the hardest, and a senior engineer should pair with the agent through the process.
The success criteria belong in the same file the agent reads, usually refactor-targets.md. That contract names every check a build server can verify: zero TypeScript errors, every existing test passing without modification, no new any types, every data-testid attribute still present, and bundle size within a defined delta of the baseline.
Here's what a minimal version looks like:
# Refactor: Consolidate button components
## Scope
Merge LegacyButton, IconButton, and PrimaryButton into a single button
component in src/components/ui/Button.tsx.
## Success criteria
- tsc --noEmit: 0 errors
- pnpm test: all passing, no skipped tests
- No new `any` types introduced
- All existing data-testid attributes preserved
- Bundle size delta < 2KB from main
Step 2: Build the safety net before the agent touches files
The safety net catches the mistakes the agent makes before they reach production. One engineer who pointed an autonomous agent at a legacy module described the result as "terrifying" — the danger is output that looks confident enough to ship without anyone catching the problem.
Get these five things in place before you let an agent edit anything beyond a single file:
Characterization tests around the target. Capture current behavior as tests before changing structure, following the pattern Nicolas Carlo recommends for untested code. Lock in whatever the code does today so you can detect drift.
Coverage thresholds as required CI gates. Set per-directory thresholds in your Vitest coverage config and fail the build when the agent's diff drops them. Don't lower a threshold to keep a refactor branch green — that's where regressions slip in.
Visual regression baselines. Take Playwright screenshot snapshots of every page and key component state on the base branch. Pixel comparisons catch CSS regressions that unit tests miss.
Type-check and lint gates in CI. Run tsc --noEmit and ESLint as required checks on the refactor branch. Agents will bypass local pre-commit hooks with --no-verify when they get stuck — the same gates need to run server-side so nothing slips through. (Steve Kinney's material on Husky and lint-stage covers why local hooks alone aren't enough for any team, let alone one running autonomous agents.)
A dedicated refactor branch with protection. Create a long-lived branch and turn on GitHub's branch protection rules so nothing lands without passing checks and a human approval.
These five gates run in CI and at the branch level — outside the agent's control. The agent itself runs inside a sandboxed environment so a misbehaving edit can't reach beyond its working directory. In OpenHands, sandboxing is on by default: Agent Canvas gives each task its own isolated runtime, so the agent can execute code, run tests, and iterate on failures without touching anything else.
Step 3: Feed the agent the right context
An agent that doesn't know your conventions will invent its own, and someone on the team has to clean up the inconsistencies later. The fix is a lightweight context file — an AGENTS.md at the repo root — that covers the canonical build commands (pnpm test, pnpm typecheck, pnpm lint), the conventions you enforce in review, and explicit constraints like "do not modify files in src/legacy/ without explicit instruction."
Keep it tight. Everything in AGENTS.md gets loaded into context on every request, so a long file crowds out the actual code the agent needs to reason about.
Concrete artifacts work better than abstract guidance. Design tokens for spacing, color, and type scale are easier for the agent to follow than a paragraph telling it to "match the existing look." For larger repos, sub-directory AGENTS.md files that activate only inside that directory work better than one monolithic root file.
Before any structural change, make the agent enumerate what it's about to touch. The first task should be something like: "List every file that imports LegacyButton, summarize each call site, and propose a migration plan." Now the agent has a written map, and every batch that follows is cheaper.
Step 4: Run the refactor in atomic, test-gated batches
Agents reliably ship refactors when the work is sliced into atomic batches with hard test gates between them. The loop is: read the code, plan the next batch, make the edits, run the tests, fix on failure, move on. The ReAct formulation (Yao et al., 2022) captures why this works — interleaving reasoning and tool calls lets the model correct course before errors compound.
Long-context pressure gets managed by externalizing state. The agent writes plans and progress notes to disk and rereads them between turns, rather than trying to hold everything in the context window.
In practice, the workflow runs in five phases:
-
Discovery: The agent scans the repo for legacy pattern usages, lists affected files grouped by type, and writes a risk-tiered task list to
refactor-targets.md. -
Batch sizing: Targets get decomposed into units that fit one context window and produce a reviewable diff. A good batch is one component folder with its test and story files — not a whole feature.
-
Atomic edits with test gates: Each batch runs behind hard gates — typecheck and the test suite must pass before the agent moves on.
-
Self-verification: The agent reruns its verification suite, retries on failure with structured error context, and falls back to a fresh context with narrower scope when retries start to spiral.
-
PR and human review: A PR opens with the diff, terminal logs, and test output attached. One human is the accountable reviewer. CI runs the same checks applied to human-authored code.
In OpenHands, separate batches run as separate agent sessions, so context from one batch doesn't bleed into the next. That isolation is what keeps batch five from inheriting the hallucinations of batch two.
Step 5: Write prompts the agent can actually finish
Most failed agent refactors come down to the prompt, not the model. A one-liner like "Convert class components to hooks" tells the agent nothing about what must stay constant or how success gets measured.
A strong prompt names the invariants the agent must preserve and the exact commands that verify the result. Here's a working example:
Migrate the Redux store in src/app to Zustand.
Preserve all existing prop interfaces.
Run pnpm lint && pnpm test && tsc --noEmit before finishing.
Do not introduce any `any` types.
When the agent fails after structured retries, don't hand-edit the generated diff — that's how you end up with a half-agent, half-human change that neither party fully understands. Discard the output, narrow the scope of the prompt, and feed the agent more context about the specific files it struggled with. A tighter prompt produces consistent diffs that the agent can keep extending.
Step 6: Pick the refactors agents finish, and flag the ones that need a human
Not every refactor is agent-shaped, and knowing where the line falls saves more time than any prompt trick. The dividing line: mechanical, consistency-oriented work with a tight test suite goes to the agent. Cross-cutting state, performance work, and security-sensitive code stays with a human who understands the runtime. We've seen teams waste weeks letting agents attempt refactors that were never going to land without a human driving — recognizing the boundary early is the highest-leverage decision in the whole process.
Agents handle these well:
Class components to hooks. Stateless and single-state class components map cleanly to function components with useState and useEffect. Complex lifecycle conversions still want human verification.
-
JavaScript to TypeScript. Agents reliably add interfaces to props and return types to functions. They reach for
anyas an escape hatch, so add@typescript-eslint/no-explicit-any: errorto ESLint first. -
CSS Modules or styled-components to Tailwind. Static styles convert reliably when the mapping is one-to-one. Constructed class names like
'bg-gradient-to-' + directionget silently missed. -
Import path updates and barrel-file restructures. Renames and barrel collapses suit agents well, because every miss surfaces as a build error.
These still need a human reviewer:
-
Cross-cutting state and authentication flows. Agents move auth-adjacent code by structural similarity, which breaks when a server-rendered context becomes client-rendered. In Next.js, the App Router migration guide treats the
"use client"directive as a rendering boundary — and the rendering boundary is what determines whether authentication logic runs on the server or the client. An agent that stamps"use client"everywhere technically makes the build pass, but it can silently move auth checks client-side. -
Performance-sensitive rendering paths. Agents aim for green tests, not render cost or bundle size. Memoization wrappers,
useMemodependencies, and lazy-loading boundaries get dropped silently because nothing in the test suite catches a performance regression. -
Pages Router to App Router migrations. Agents typically overuse
"use client"and convertgetServerSidePropsto fetch-based route handlers when the correct path is usually a server component or server action. -
Anything touching payments, PII, or authentication. These changes need an explicit owner signing off on the diff, not an agent operating against a checklist.
How OpenHands runs end-to-end frontend refactors
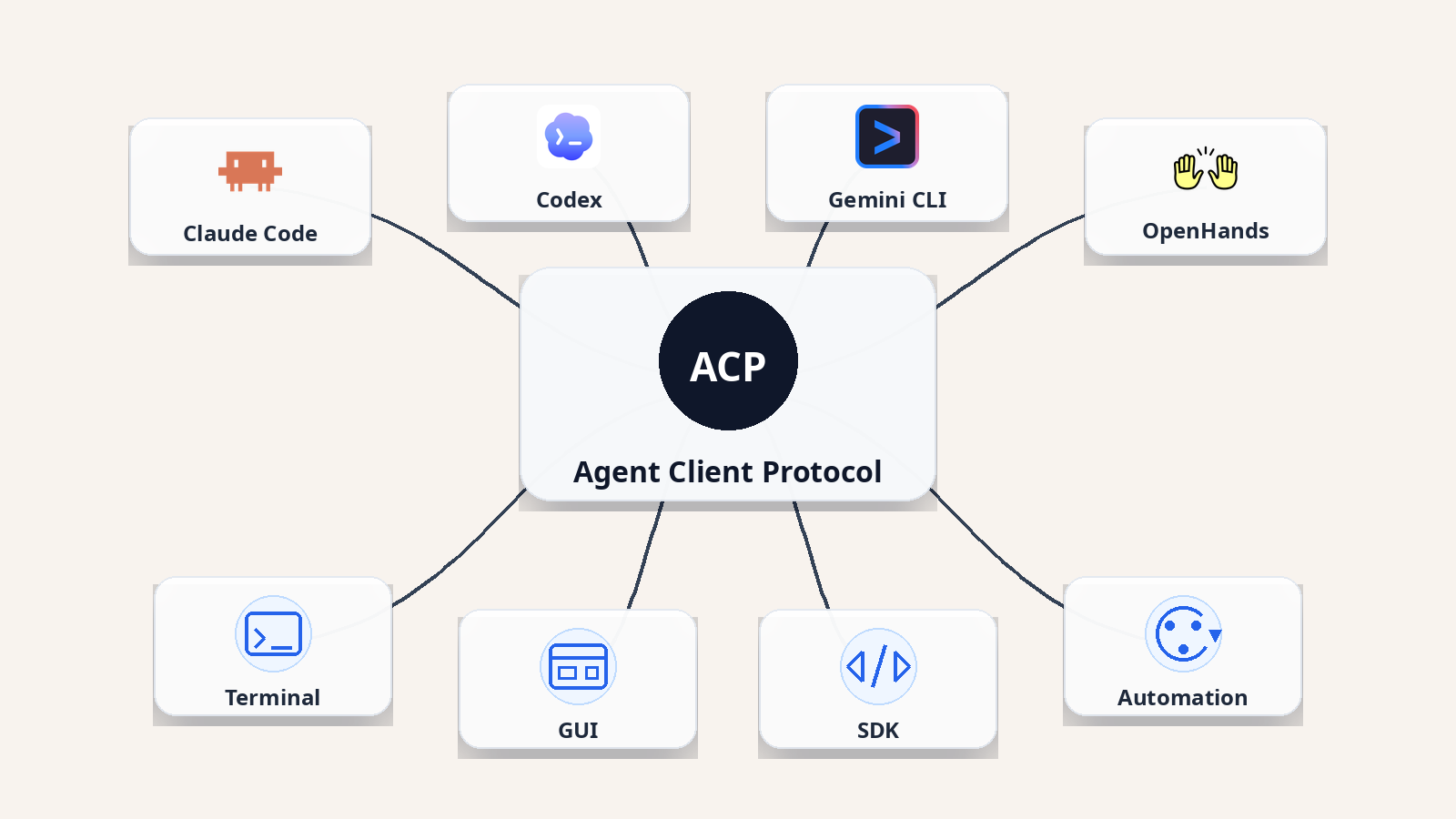
OpenHands ties the workflow above together into a single platform. Agent Canvas keeps the agent's reasoning, batches, and verification runs in one workspace, so you review the work in the same place the agent runs it. Because it connects to your existing coding agents through the Agent Client Protocol, you don't have to switch tools — whatever agent you're already paying for plugs in directly.
For refactors too large for a single agent session — a monorepo with shared component libraries across multiple apps, for instance — the Large Codebase SDK extends this workflow. It maps dependencies across the codebase and orchestrates multiple agents in parallel against independent slices, so the work scales without producing conflicting edits.
The platform runs in three configurations: locally through Agent Canvas, in OpenHands Cloud for teams that want shared runs without managing infrastructure, and as a self-hosted Enterprise deployment inside your VPC for regulated codebases. The audit log tracks which refactors finished cleanly and which need follow-up — useful for the team lead who needs to know the state of a migration without reading every diff.
Putting an agent on your next frontend refactor
The pattern that works is simple: scope the change, write the success criteria, build the safety net, and let the agent run atomic batches against a tight prompt. Mechanical refactors come out as reviewable diffs. Architectural decisions stay with the engineers who own the system.
The part most teams underestimate is the setup. The agent is only as good as the contract you give it — the refactor-targets.md, the AGENTS.md, the CI gates. Skip those, and you'll spend more time cleaning up the agent's output than you would have spent doing the refactor by hand. Get them right, and the agent grinds through the tedious file-by-file work while your senior engineers spend their time on the decisions that actually need a human.
Pick a refactor that's been sitting on the backlog and try the workflow. OpenHands is free to run locally — start there and see how the output holds up under review.
Frequently asked questions about AI refactoring frontend code
What if the agent breaks something and we don't catch it?
That's what the safety net is for, and it's why Step 2 exists before the agent writes a single line. Characterization tests lock in current behavior. Visual regression baselines catch what unit tests miss. CI gates run tsc and ESLint on every commit. Branch protection ensures nothing merges without passing checks and a human approval. The risk isn't zero, but it's bounded — and the same gates that catch agent mistakes also catch human ones. The OpenHands quickstart walks through sandboxing and branch setup.
How much setup time does this actually take?
The honest answer: a few hours up front, less on the second refactor. Writing refactor-targets.md and AGENTS.md, adding characterization tests, and configuring CI gates is real work. But it's work you'd want for a human-driven refactor too — the agent just forces you to do it explicitly instead of carrying the context in someone's head. Teams that skip the setup spend more time cleaning up agent output than they save.
Our codebase is too large for a single agent session. Does this still work?
Yes. The Large Codebase SDK maps dependencies across the codebase and orchestrates multiple agents in parallel against independent slices. Each agent works on a bounded piece — one module, one component library — and the SDK prevents conflicting edits. The OpenHands SDK docs cover integration points for running the same orchestration inside CI or internal tooling.
When should we self-host instead of using the cloud version?
Self-hosting is the right call when regulated data, air-gapped requirements, or strict audit logging rule out anything outside your perimeter. If your security team needs to sign off on where agent inference happens and where code is stored, that's the signal. OpenHands Enterprise runs inside your VPC with RBAC, full audit trails, and the same controls your platform team applies to the rest of your infrastructure.
.png)

Get useful insights in our blog
Insights and updates from the OpenHands team
Sign up for our newsletter for updates, events, and community insights.
OpenHands is the foundation for secure, transparent, model-agnostic coding agents - empowering every software team to build faster with full control.



