The OpenHands Index: 3 Months Out
Written by
Juan Michelini, Graham Neubig
Published on
The OpenHands Index is a leaderboard that evaluates language models across a range of software engineering tasks: issue resolution, building greenfield apps, frontend development, software testing, and information gathering. It measures not just accuracy, but also cost and runtime, so you can pick the model that fits your tasks.
We released the OpenHands Index three months ago, and a lot has happened since then!
The most important thing is that we have added a bunch of new models across the board: we have representatives from both the big frontier labs like Anthropic, OpenAI, and Google DeepMind, as well as startups like DeepSeek, z.ai, and Minimax, and new entrants such as NVIDIA. Let’s look at the results!
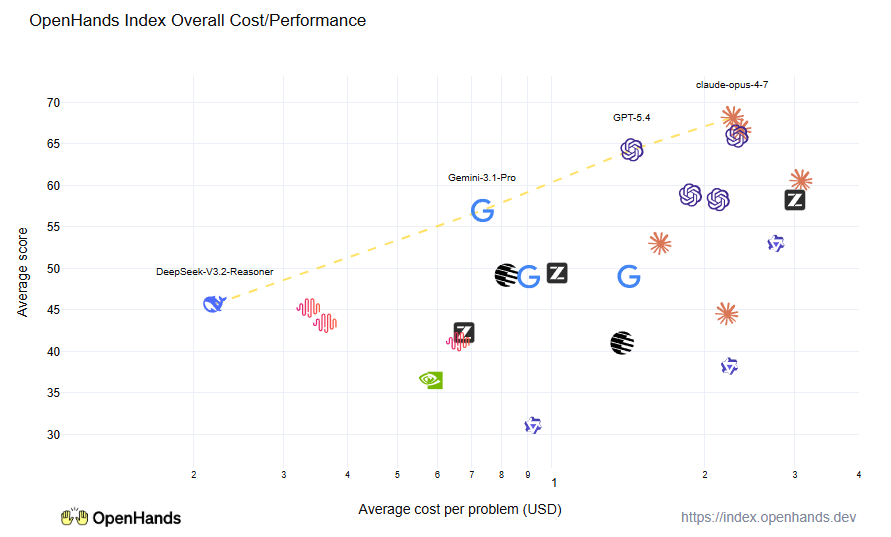
First, cost/performance, our main graph. We can see that overall Opus 4.7 takes the top spot, although GPT-5.5 is very competitive (it’s the OpenAI logo right next to Opus). GPT-5.4 does very well at a bit of a cheaper price point, and Gemini 3.1 Pro does well at even cheaper. Our least expensive contender DeepSeek-3.2-Thinker is very solid at 1/10 the price of Claude.
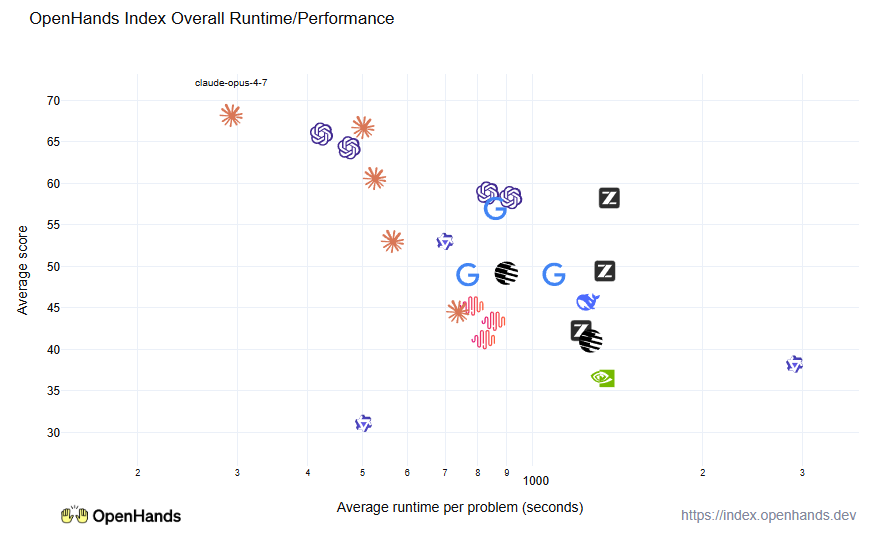
We also measure time to resolution for issues, since having quick responses can be important. Here we can see that the Claude and GPT models perform the best — they’re able to use effective parallel tool calling and efficient inference to finish problems quickly.
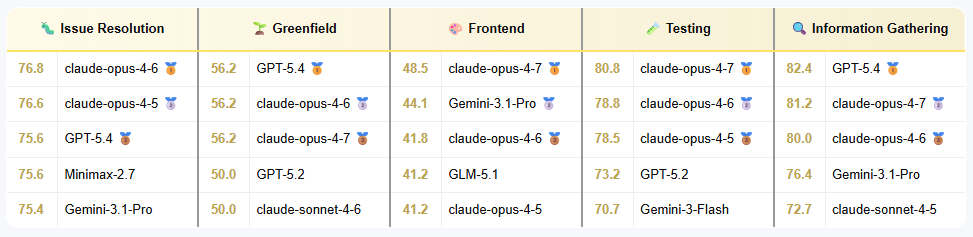
Let’s look at the task-by-task breakdown. For resolving issues on Python repos (SWE-Bench), it’s a competitive field, with many models getting good results. For greenfield, long-horizon development, we see Claude and GPT take the show, they are very strong at performing big, long-running tasks. For frontend development, Claude and Gemini are strong, reflecting their strong multimodal capabilities and the new Claude Opus 4.7 stands out from the pack. But GLM-5.1 also takes close to a top place, a strong contender in where open models have struggled previously. For software testing, Claude is the run-away winner, it seems to have very strong debugging skills! And finally for information gathering, GPT takes the top, although Claude also has a strong showing.
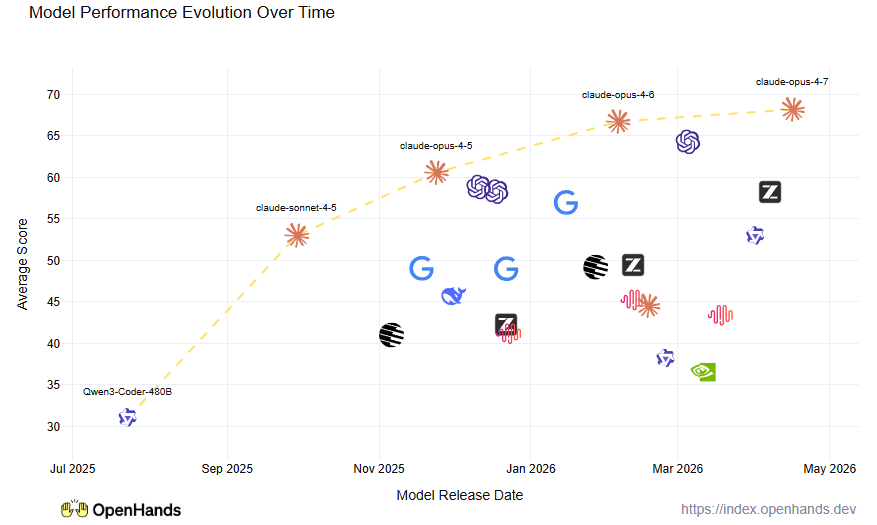
Finally, since we have been doing the index for a while now, we’re starting to get a picture of how models evolve over time! It seems that Claude is consistently a few months ahead of the trend, followed by GPT, and then the others in the pack.
We’re looking to do some more frequent updates going forward, so watch this space when new models come out! And if you have any requests please feel free to ping us on X, LinkedIn, or Slack.
.png)

Get useful insights in our blog
Insights and updates from the OpenHands team
Sign up for our newsletter for updates, events, and community insights.
OpenHands is the foundation for secure, transparent, model-agnostic coding agents - empowering every software team to build faster with full control.



